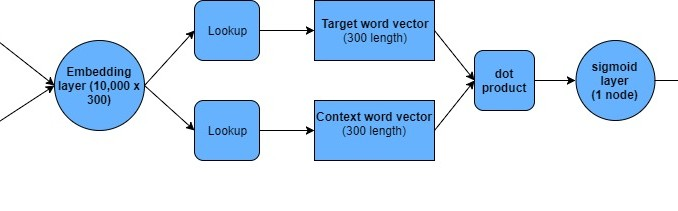
Background
I have came across a few articles that clear some of misconceptions around advanced analytics. Two of them, DataOps is NOT Just DevOps for Data and The Next Big Challenge for Data is Organizational has been my favorite.
I cherry-picked some of ideas from them, try to apply them to my work context, turns out it helped a lot to set my expectation correctly and align my plan with the overall organizational vision and strategy.
Here are some punch lines:
The fundamentally different between data warehousing and the advanced analytics (or machine learning application) is that the first one is value pipeline and the later is the innovation pipeline. Some other finding is derived from that perspective.
It’s the organizational factor that challenge data or advanced analytics projects.
The first one set the tone for the second one, while the second one will make fundamental change to your organization’s data approach ( sometimes can be right v.s wrong, rather than just different.).