原文:http://adventuresinmachinelearning.com/word2vec-keras-tutorial/
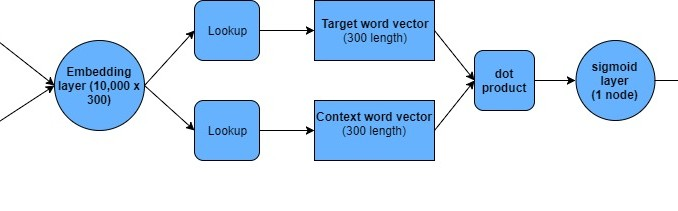
Word2Vec负取样架构图
理解Word2Vec的词嵌入对学习机器学习来说至关重要。 词嵌入也是自然语言处理的关键一步。 本教程展示如何利用深度学习框架Keras来实现Word2Vec。关于Keras的介绍,请参考我的另外一篇文章。在我的前一篇文章里,我介绍了基于TensorFlow的Word2Vec实现,并且说明了一个简单的、基于softmax的机制在大词量,训练嵌入层相当慢的情况的情况,通过引入了"negative sampling"的机制,并且在tensorflow中定制了loss function,即nce_loss来解决问题。
可惜Keras没有这个损失函数,所以在本文中我们会自己实现。通过自己实现的过程,反而能帮助我们理解负取样的机制,进而更理解Keras的Word2Vec的过程。
词嵌入
如果我们要利用文档来训练一个自然语言机器学习系统,我们需要文档中常用词的词典。有时候词典会包含超过一万个单词。一个简易的方式是通过叫做 “one-hot”向量来标识学习模型中的一个单词。比如,用一个10000个0的向量,只有唯一一个为1,而这个1的位置可以标识一个单词。当然这个方法很低效,一万维的向量很难训练。并且这样的向量里也丢失了单词含义、单词的使用场景和常用的上下文,比如这个词通常跟哪些词出现在一起。
而词嵌入则通过“压缩”巨大的 “one-hot”向量变成维度小得多的向量(几百维),并且里面保留了单词的一些含义和词的上下文。Word2Vec式词嵌入式中最常用的方法,本文下文将继续深入解析。
上下文、Word2Vec和skip-gram模型
Word2Vec主要依赖单词的上下文来衡量单词的含义。比如一个句子:the cat sat on the mat中 sat的上下文包括: the、cat、on、the、mat。也就是说这些词通常出现在sat周围。在Word2Vec中,拥有类似上下文的单词也有类似的含义,而他们之间的向量也类似。在skip-gram版本的Word2Vec中,主要任务就是拿到一个诸如 sat的单词来预测他周围的词。这需要一个不断迭代的学习过程。
学习的最终结果则是网络模型中的嵌入层,该嵌入层类似一个对照表,表中的每一个行向量代表了一个词典中的单词。下例为一个简化的向量,以词典大小为7、嵌入层大小为3为例:
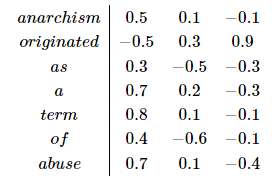
如上图所示:每个词(行)由一个3维向量表示。这样的嵌入层(或者说对照表)可以通过训练一个简单的神经网络和一个softmax的输出层实现。如下图所示:
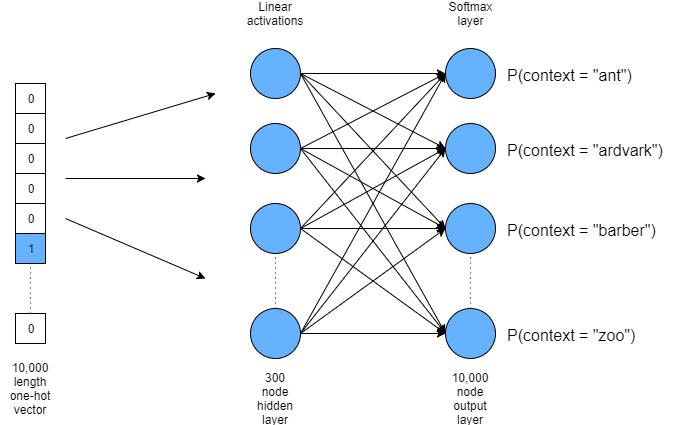
上图所示的神经网络的主要思路是:首先将目标单词做为 “one-hot”向量的形式输入;然后通过一层隐藏层,我们试图训练神经网络以达到提升上下文相关词的概率,而降低非上下文相关词(即从未出现在目标词周围的词)的概率。这需要在输出层中引入一个softmax函数。一旦训练完毕,输出层被丢弃而我们所需要的就只是隐藏层的权重。 Word2Vec有两种形式:skip-gram和CBOW。前者已知目标词来预测上下文词,而后者则用上下文词来预测目标单词。本文将以skip-gram为例。
Softmax问题和负采样
用完整的softmax输出层的问题是计算成本非常高昂,例如下面的等式:
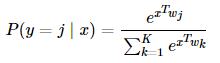
结果为类型j的可能性的值由隐藏层的输出乘以到达输出层的权重得到,然后除以全部类型(j以外)的同样的计算之和。当输出为一个10000维的“one-hot”向量,在训练中做gradient decent的时候就有上百万的权重需要更新。这样计算很费时间,正如我再上一篇文章中提到的那样。 另外一个办法是负采样,Mikolov 在他最初的论文里有提到。他的思路是加强目标单词到上下文词的权重,另外他并不直接减少非上下文单词的权重,而是只从中取出一部分样本,这些样本就叫做负采样。
为了训练嵌入层,我们使用Keras中的negative samples,我们需要重新理解训练的方式,我们不用多类别的softmax层的网络结构,而是一个简单的二元分类器:对上下文相关的单词,我们希望网络输出为1,而非相关的取样词,输出则为0。因此Keras中的Word2Vec网络结果就是一个单节点的sigmoid激活函数。 在训练网络模型的过程中,我们需要确保具有相似含义的单词也具有类似的嵌入向量。因此我要确保训练好的网络对上下文相关的单词总是输出1,反之则为0。因此在输出的sigmoid层中引入一个向量相似度得分—相似的向量输出高分,反之则低分。最典型的方式是用cosine相似得分:
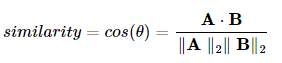
式子中的分母用来归一化结果,实际的相似度计算主要看分子: 向量A和B的点积。也就是说如果不用归一化,直接用两个向量的点积就可以了。 有了这些概念,基于Keras的Word2Vec的负采样网络具有如下特点:
- 一个整型的目标单词和一个上下文相关单词或者上下文不相关单词。
- 一个嵌入层,比如用单词在嵌入矩阵中的下标查询单词的向量表示。
- 点积操作
- 输出的sigmoid层。
实现的架构如下图所示:

我们仔细过一遍这个架构:首先,词典里的每个单词都用一个整数来表示,整数范围从0到字典尺寸(我们这里是10000),然后将两个单词传入这个模型,一个是目标单词,另外一个上下文相关或者不相关单词。我们从嵌入层(一个10000 x 300的张量)中的行做为一个词的向量。接着对这两个向量进行点积得到相似度。最后将计算结果输出到sigmoid层,结果得到1或者0,然后跟标签对比(标签中1为上下文相关、0为上下文不相关)。 通过反向传播算法,不断调整模型的权重,最后达到真正相似的词拥有相似性较高的向量。我们下面用keras来实现这个结构,并测试是否真的可行。
Word2Vec的Keras实现
这段展示如何通过Keras实现Word2Vec,全部的代码托管在GitHub的库中。
数据解析
实现Word2Vec首先需要数据,在上一篇Word2Vec的TensorFlow的教程中,我们用了来自这里的数据,我会用同样的解压函数(尤其是collect_data)来提取数据中的信息。请参阅前面的Word2Vec教程。简单来说,这个函数调用其他函数来下载数据,然后又函数将文本数据转到一系列的整型数字,一个数字代表了词典里的唯一的一个单词。下面是这个函数的调用过程:
vocab_size = 10000
data, count, dictionary, reverse_dictionary = collect_data(vocabulary_size=vocab_size)
集合中的头7个单词是: [‘anarchism’, ‘originated’, ‘as’, ‘a’, ‘term’, ‘of’, ‘abuse’] 调用了collect_data之后,这些单词的标识为: [5239, 3082, 12, 6, 195, 2, 3134] Collect_data返回了两个词典,第一个通过单词查找整型标识,第二个则刚好相反,通过整型标识来查找实际对应的单词。
接下来,我们要定义一些常量,并建立一个用来验证词集合,用来在训练过程中检验学习进展。
常量和验证词
window_size = 3
vector_dim = 300
epochs = 1000000
valid_size = 16 # Random set of words to evaluate similarity on.
valid_window = 100 # Only pick dev samples in the head of the distribution.
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
window_size表示目标单词周围的能作为上下文的窗口大小。第二个常量,vector_dim,是词向量的尺寸,我们这里用10000 x 300。最后我们用了一个很大的循环值,表示我们要进行学习迭代的次数。即使用了negative sampling,词嵌入的学习还是很费时间的。
接下来的一组代码是我们要检验的单词,用来对照其他单词跟这些词的相似性。在训练过程中我们会检查这些词的词向量和系统认为跟这些词向量类似的词,确保系统认为类似的词跟我们理解的语义相似的词是否一致。这里我们从词典中的最常用的100个单词中随机选择16个(collect_data函数已经将最常用的单词按照降序排列返回,比如第一个单词是最常见得,第二个单词次之)。 接下来我们看看Keras中和实用的一个函数,他为我们处理了所有skip-gram和上下文处理的相关工作。
Keras中的skip-gram函数
为了用skip-gram和负采样方法,我们必须创建包含真的上下文单词和非上下文单词。而这则需要扫描整个数据集并选择目标单词,然后随机地从目标词前后窗口长度范围内选择上下文相关单词。例如句子“the cat sat on the mat”句子中目标词为 “on”,窗口尺寸大小为2,则单词“cat”、“set”、 “the”, “mat”都有可能被选为上下文单词。当然也需要从窗口尺寸之外的范围选择非上下文单词。最后需要根据选择的单词是否为上下文相关单词,将标签设置为1或者0。Keras中有一个函数(skipgrams)能够全部实现上述功能,代码如下:
sampling_table = sequence.make_sampling_table(vocab_size)
couples, labels = skipgrams(data, vocab_size, window_size=window_size, sampling_table=sampling_table)
word_target, word_context = zip(*couples)
word_target = np.array(word_target, dtype="int32")
word_context = np.array(word_context, dtype="int32")
print(couples[:10], labels[:10])
暂时先忽略第一行代码,Keras的skip-gram函数正是我们想要的结果:他返回了一个目标单词-上下文单词的元组,并且返回了是否为上下文相关单词的标签。他默认返回洗牌过的数据。这个结果随后被分成单独的目标单词和上下文单词,并确保数据类型是合适的类型,最后一行的打印函数输出结果如下: couples: [[6503, 5], [187, 6754], [1154, 3870], [670, 1450], [4554, 1], [1037, 250], [734, 4521], [1398, 7], [4495, 3374], [2881, 8637]] labels: [1, 0, 1, 0, 1, 1, 0, 1, 0, 0]
前面提到的第一行代码中的make_sample_table操作创建了一个表,skipgrams会用他来确保负取样的结果是平衡的而不是只有最常见的单词。 创建好的数组会被传入到Keras的模型中,这里再着重讲一下Keras中的Word2Vec模型本身。
Keras的Functional借口和嵌入层
用Keras实现Word2Vec时,我们会用到Keras的functional API,在我之前的Keras教程里,我就用咯额Keras的sequential层功能。Sequential层框架能方便地讲各层链接起来,将上一层输出的张量很容易地就能输入到下一层。在本例中我们会用一些小花招,通过在两个张量间共享一个嵌入层,并通过一个辅助的输出层来验证相似性,因此我们不能直接使用sequential的实现。
幸好functional的API容易上手,我会通过讲解代码来介绍functional API。第一步,我们需要按照上文提到的网络结构构件模型。首先需要初始化输入变量和嵌入层。
# create some input variables
input_target = Input((1,))
input_context = Input((1,))
embedding = Embedding(vocab_size, vector_dim, input_length=1, name='embedding')
首先我们需要指定什么样的张量(以及大小)将要输入到模型中。在本例中,我们会输入单个目标词和上下文相关词,所以每个输入变量大小为(1,)。接下来,我要创建一个嵌入层,这里Keras其实已经为我们创建好了即调用Embedding()。方法的地一个参数是嵌入层的行数,也就是词典的大小(10000),第二个参数是每个单词的嵌入向量(也就是列)大小,我们这里是300。我们也指定了输入大小,这里也就是输入变量大小,就是前面指定过的1。最后我们给层取一个名字,当我们要回头来查看层的权重时,我们可以通过名字来查找。
层的初始权重是自动生成的,当然你也可以向一个embeddings_initializer的参数传入一个Keras的初始化对象。接下来,我们需要通过目标词和上下文词的一个整型的编号来查找对应的词向量:
target = embedding(input_target)
target = Reshape((vector_dim, 1))(target)
context = embedding(input_context)
context = Reshape((vector_dim, 1))(context)
如上述代码所示,可以向之前创建的embedding层通过一个整型数据获得词向量。再通过Reshape方法让词向量方便进行后续的点积和相似度计算。
接下来的一层进行两个词向量的cosine相似度计算。
# setup a cosine similarity operation which will be output in a secondary model
similarity = merge([target, context], mode='cos', dot_axes=0)
Keras提供了一个merge操作,可以通过给mode参数传入“cos”来结算两个向量的cosine相似度。真正的相似度结果会通过另外一个模型来输出,这个我们后续再讲。
回到我们之前讲的架构的模型,我们会在主要流程里的负取样架构中用点积作为衡量相似度的方法。
# now perform the dot product operation to get a similarity measure
dot_product = merge([target, context], mode='dot', dot_axes=1)
ot_product = Reshape((1,))(dot_product)
# add the sigmoid output layer
output = Dense(1, activation='sigmoid')(dot_product)
我们再用Keras的merge功能,对目标单词和上下文单词的词向量进行点积操作。然后再做一次Reshape,拿着一个为标量的结果输入给Dense层,用一个sigmoid激活函数。这样就的到Word2Vec的输出。
接下来,我们补充模型所需信息并进行编译就可以进行训练了。
# create the primary training model
model = Model(input=[input_target, input_context], output=output)
model.compile(loss='binary_crossentropy', optimizer='rmsprop')
我们这里用了基于functional API的模型来实现Word2Vec的架构,模型定义需要模型的输入类型为numpy的数组和输出张量。这些我们都已经在前面定义好了。传入了应用到输出变量的名为binary_crossentropy的损失函数和一个名为rmsprop的优化器之后就可以编译了。
有个问题:如果我们应该如何想用前面定义的similarity操作来检查训练的进度?答案是我们可以用model的定义来输出,但是这样的话Keras会把这个当作训练集,这不是我们期望的。 解决办法是创建另外一个模型。
# create a secondary validation model to run our similarity checks during training
validation_model = Model(input=[input_target, input_context], output=similarity)
我们现在可以用validation_model来调用similarity操作,并且这个模型和主模型的嵌入层是同一个。需要注意的是,我们并不需要真正训练这个模型,所以我们不需要编译这个模型。 这样就可以开始训练模型了,在此之前,我们定义一个valid_example函数来打印出和验证集中的单词最相似的单词。
相似度回调函数
这个函数用来打印出和测试集最相似的单词来监控训练的进度。
class SimilarityCallback: def run_sim(self): for i in range(valid_size): valid_word = reverse_dictionary[valid_examples[i]] top_k = 8 # number of nearest neighbors sim = self._get_sim(valid_examples[i]) nearest = (-sim).argsort()[1:top_k + 1] log_str = 'Nearest to %s:' % valid_word for k in range(top_k): close_word = reverse_dictionary[nearest[k]] log_str = '%s %s,' % (log_str, close_word) print(log_str) @staticmethod def _get_sim(valid_word_idx): sim = np.zeros((vocab_size,)) in_arr1 = np.zeros((1,)) in_arr2 = np.zeros((1,)) for i in range(vocab_size): in_arr1[0,] = valid_word_idx in_arr2[0,] = i out = validation_model.predict_on_batch([in_arr1, in_arr2]) sim[i] = out return sim sim_cb = SimilarityCallback()
这个方法遍历所有的验证集,并和其他所有单词计算相似度。相似度函数_get_sim()调用model里的predict_on_batch()操作。也就是从嵌入层中找到两个词向量,并返回两个向量的相似度。外面的一层循环把相似度结果按降序排列,并打印出最相似的前8个单词。我们将在训练的循环中调用这个函数,具体代码如下:
arr_1 = np.zeros((1,))
arr_2 = np.zeros((1,))
arr_3 = np.zeros((1,))
for cnt in range(epochs):
idx = np.random.randint(0, len(labels)-1)
arr_1[0,] = word_target[idx]
arr_2[0,] = word_context[idx]
arr_3[0,] = labels[idx]
loss = model.train_on_batch([arr_1, arr_2], arr_3)
if i % 100 == 0:
print("Iteration {}, loss={}".format(cnt, loss))
if cnt % 10000 == 0:
sim_cb.run_sim()
我们需要循环之前制定的训练迭代次数,第一步:随机选择一个下标,拿到对应的目标单词,上下文单词和结果标签,放到numpy数组中。接着拿着这个数组放到主模型中运行train_on_bactch()操作,返回的是当前的损失函数值并打印出来,每10000次循环还会调用前面定义的回调函数。
下面是一些回调的验证函数输出的“eight”这个单词的近似词。 Iterations = 0: Nearest to eight: much, holocaust, representations, density, fire, senators, dirty, fc Iterations = 50,000: Nearest to eight: six, finest, championships, mathematical, floor, pg, smoke, recurring Iterations = 200,000: Nearest to eight: six, five, two, one, nine, seven, three, four
从中我们可以看到,开始时,“six”这个词的近似词是随机分配的。随着训练的进行,其他表示数字的单词开始成为“six”的相似词,而最终所有8个近似词都是表示数字的单词。
这样就算是完整的结果了。回顾一下:本教程介绍了Word2Vec和负取样是如何工作的,如何用Keras的functional 接口实现,而在接下来的教程里,我会就介绍如何在Keras和Tensorflow中载入训练好的嵌入权重。